
Hadoop伪分布式环境搭建(ubuntu14.04)
一、java环境搭建
参考博客:http://blog.csdn.net/best3c/article/details/72848540
1、安装JDK
1.1新建一个java文件夹名字叫java7u79
1.2将linux版本的jdk安装包从宿主机复制进客人机(客户机),一般直接可以拖进来,
然后拷贝·进/usr/java7u79目录
1.3 进入/usr/java7u79目录解压jdk包
1.4 进入配置文件

1.5 配置完后,esc退出编辑模式,:wq保存退出环境配置
1.6检测java环境

二、 hadoop环境搭建
本教程使用 Ubuntu 14.04 64位 作为系统环境
- 创建hadoop用户
1.1 如果安装ubuntu时没有创建hadoop用户,此时就增加一个hadoop用户。
1.2 为hadoop用户设置密码
1.3 为hadoop用户添加管理员权限,方便部署,避免一些新手关于权限的麻烦
1.4 shut –h now 关机
2、安装SSH、配置SSH无密码登录
2.1 节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server
2.2登录本机
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。
2.3登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost
2.4再次ssh localhost就可以不用密码登录
3、hadoop下载安装
Hadoop各版本:http://archive.apache.org/dist/hadoop/core/
3.1 解压hadoop.x.y.tar.gz
我这里解压到/usr下
tar –zxvf hadoop-2.6.0.tar.gz
解压到指定目录时,直接 tar –zxvf hadoop-2.6.0.tar.gz –C /usr
#可以试着修改文件名,我这里先不用修改了
mv ./hadoop-2.6.0 ./hadoop
3.2 切换到hadoop文件目录查看hadoop版本信息
|
|
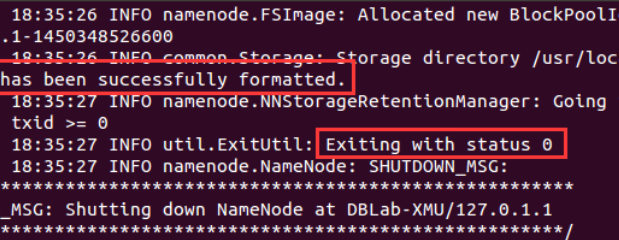
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错。
4.4开启NameNode和DataNode守护
./sbin/start-dfs.sh
这个步骤就算JAVA_HOME没有配置错误也可能会找不到JAVA路径
Hadoop安装完后,启动时报Error: JAVA_HOME is not set and could not be found.
解决办法:修改/etc/hadoop/hadoop-env.sh中设JAVA_HOME
路径改为绝对路径
Export JAVA_HOME=${JAVA_HOME}改为Export JAVA_HOME=/usr/java7u79/java1.7.0_79
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。
4.5 成功启动
可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
4.6打开或者关闭hadoop
切换到hadoop目录下
./sbin/stop-dfs.sh
./sbin/start-dfs.sh
5、YARN启动(伪分布式不启动 YARN 也可以,一般不会影响程序执行)
5.1 YARN简介
YARN 是从 MapReduce 中分离出来的,负责资源管理与任务调度。YARN 运行于 MapReduce 之上,提供了高可用性、高扩展性
通过 ./sbin/start-dfs.sh 启动 Hadoop,仅仅是启动了 MapReduce 环境,我们可以启动 YARN ,让 YARN 来负责资源管理与任务调度。
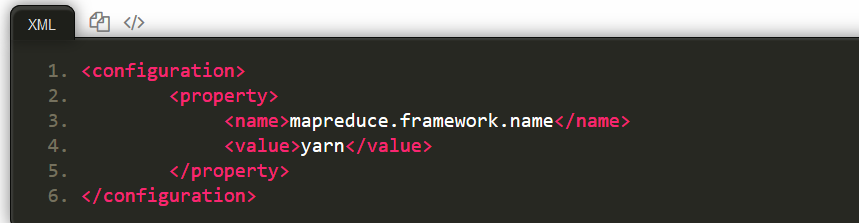
5.2 修改配置文件 mapred-site.xml,这边需要先进行重命名
5.3 然后再进行编辑 vim ./etc/hadoop/mapred-site.xml
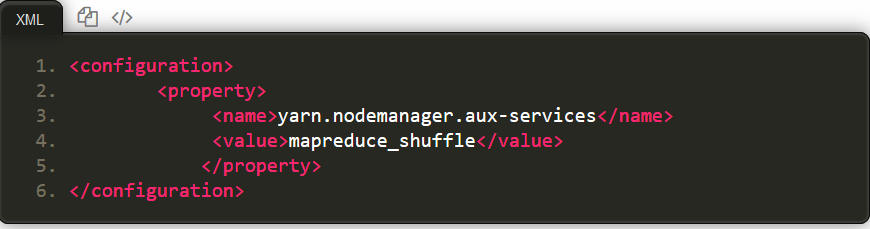
5.4修改配置文件 yarn-site.xml
5.5启动YARN(启动之前先启动hadoop)
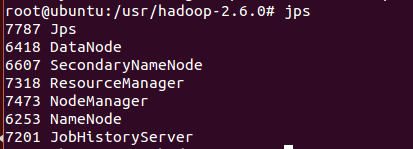
5.6 ps查看,可以看到多了 NodeManager 和 ResourceManager 两个后台进程,如下图所示。
5.7 YARN启动和关闭(单机若无需要不建议开启YARN,使用反而会使程序变慢)
